1 前言
ZAB协议全称:Zookeeper Atomic Broadcast,即Zookeeper 原子广播协议。而ZooKeeper是一个开放源代码的分布式协调服务,由知名互联网公司雅虎创建,是Google Chubby的开源实现。ZooKeeper的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
ZooKeeper是一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
在一致性算法上,ZooKeeper采用了ZAB,但其并不是Paxos算法的实现,也不是一种通用的分布式一致性算法,而是一种改进的、专为ZooKeeper服务设计的崩溃可恢复的原子消息广播算法。
2 原理
Zookeeper根据ZAB协议建立了主备模型完成Zookeeper集群中数据的同步。这里的主备模型具体是指ZooKeeper使用一个单一的主进程(Leader)来接收并处理客户端的所有事务请求,并采用ZAB的原子广播协议,将服务器数据的状态变更以事务Proposal的形式广播到所有的副本进程(Follower)上去。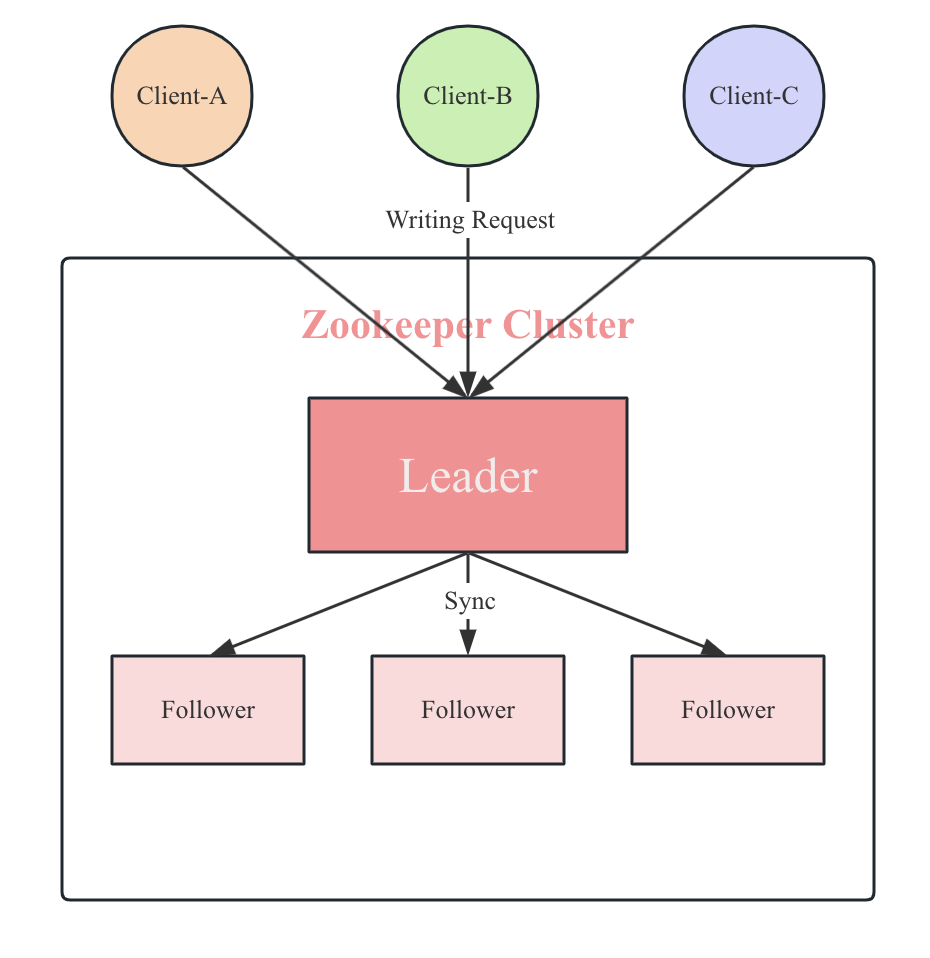
ZAB协议的核心就是:
在整个
Zookeeper集群中,所有事务请求必须由一个全局唯一的服务器,即Leader服务器来协调处理,而余下的其他服务器则成为Follower 服务器。Leader 服务器负责将一个客户端事务请求转换成一个事务 Proposal(提议),并将该 Proposal 分发给集群中所有的Follower服务器。之后 Leader 服务器需要等待所有 Follower 服务器的反馈,一旦超过半数的 Follower 服务器进行了正确地反馈后,那么Leader就会再次向所有的 Follower服务器分发Commit消息,要求其将前一个Proposal进行提交。
3 两种基本模式
ZAB协议包括两种基本的模式,分别是崩溃恢复和消息广播。
- 当整个服务框架在启动过程中,或是当Leader服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进入
恢复模式并选举产生新的 Leader 服务器。 - 当选举产生了新的Leader服务器,同时集群中已经有过半的机器与该Leader服务器完成了
状态同步之后,ZAB协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和Leader服务器的数据状态保持一致。此时整个服务框架就可以进入消息广播模式了。如果此时集群中已经存在一个
Leader服务器在负责进行消息广播,那么新加入的服务器就会自觉地进入数据恢复模式。Leader 服务器是Zookeeper集群中唯一一个用来处理事务请求的角色。Leader 服务器在接收到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议;- 而如果集群中的其他机器(Follower)接收到客户端的
事务请求,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器。
- 当
Leader服务器出现崩溃退出或机器重启,亦或是集群中已经不存在过半的服务器与该Leader服务器保持正常通信时,那么在重新开始新一轮的原子广播事务操作之前,所有进程首先会使用崩溃恢复协议来使彼此达到一个一致的状态,于是整个 ZAB 流程就会从消息广播模式进入到崩溃恢复模式。整个 Zookeeper 就是在这两个模式之间切换。 简而言之,当 Leader 服务可以
正常使用,就进入消息广播模式,当 Leader不可用时,则进入崩溃恢复模式。3.1 消息广播
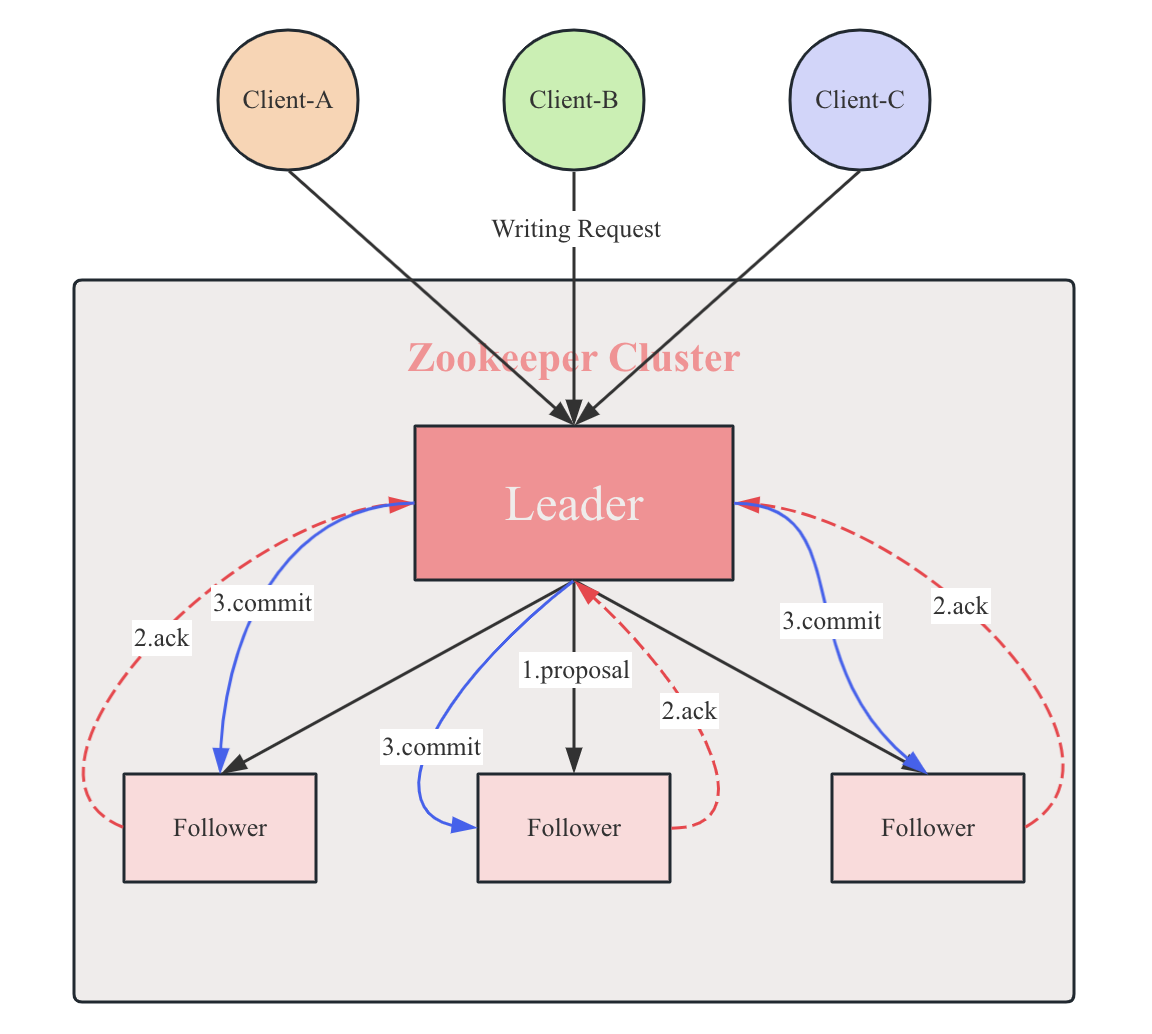
ZAB协议的消息广播过程使用的是一个原子广播协议,类似于一个二阶段提交过程。针对客户端的事务请求,Leader服务器会为其生成对应的事务Proposal,并将其发送给集群中其余所有的机器,然后再分别收集各自的选票,如果超过半数成功响应,则进行事务提交。
具体步骤如下:
- 客户端发起一个写操作请求;
- Leader服务器将客户端的
request请求转化为事物proposal提案,同时为每个proposal分配一个全局唯一的ID,即ZXID; - Leader服务器与每个follower之间都有一个
队列,Leader将消息发送到该队列; - follower机器从
队列中取出消息处理完(写入本地事物日志中)毕后,向Leader服务器发送ACK确认; - Leader服务器收到
半数以上的follower的ACK后,即认为可以发送commit; - Leader向所有的follower服务器发送
commit消息。
这个流程如下图所示: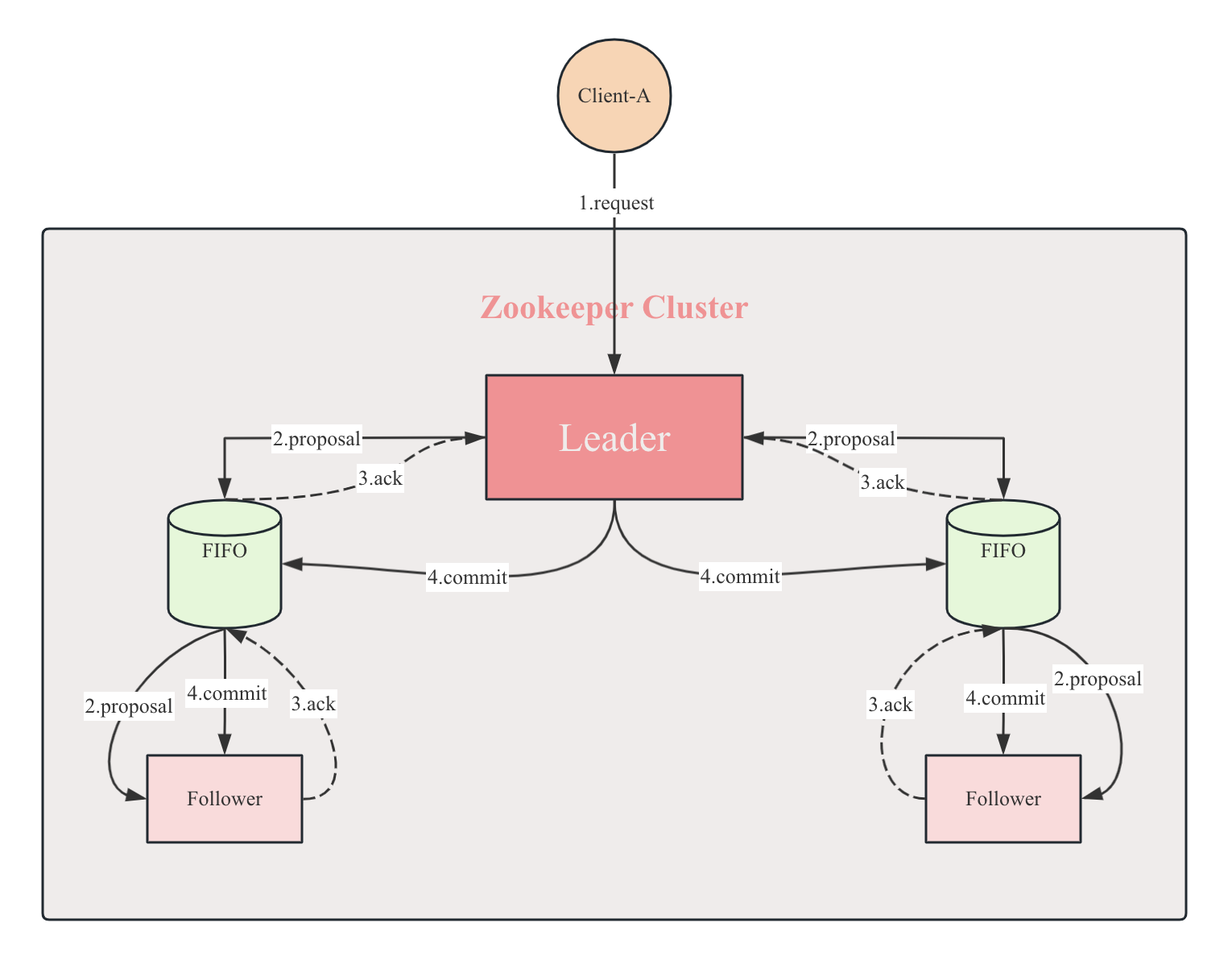
3.2 崩溃恢复
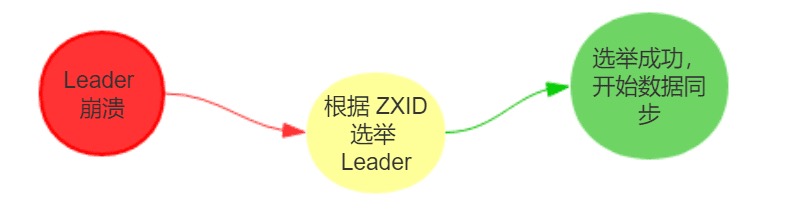
- 假设一个事务在 Leader 服务器上被提交了,并且已经得到
过半Follower 服务器的Ack反馈,但是在它将Commit消息发送给所有Follower机器之前,Leader服务器挂了; - 假设初始的 Leader 服务器 Server1 在提出了一个事务
Proposal-3之后就崩溃退出了,从而导致集群中的其他服务器都没有收到这个事务Proposal。
针对这些问题,ZAB 定义了 2 个原则:
原则一:ZAB 协议确保那些已经在 Leader 提交的事务最终会被所有服务器提交。原则二:ZAB 协议确保丢弃那些只在 Leader 提出/复制,但没有提交的事务。
3.2.1 Leader选举
所以,ZAB 设计了下面这样一个选举算法:能够确保提交已经被 Leader 提交的事务,同时丢弃只在Leader服务器上被提出的事务。
针对这个要求,如果让 Leader 选举算法能够保证新选举出来的 Leader 服务器拥有集群中所有机器编号(即 ZXID 最大)的事务,那么就能够保证这个新选举出来的 Leader 一定具有所有已经提交的提案。而且这么做有一个好处是:可以省去 Leader 服务器检查事务的提交和丢弃工作的这一步操作。
详细Leader选举过程,可参考我写的这篇文章1。
3.2.2 数据同步
完成Leader选举之后,在正式开始工作(即接收客户端的事务请求,然后提出新的提案)之前,Leader服务器会首先确认事务日志中的所有Proposal是否都已经被集群中过半的机器提交了,即是否完成数据同步。目的是为了保持数据一致。
当所有的 Follower 服务器都成功同步之后,Leader 会将这些服务器加入到可用服务器列表中。参见3.2节开头崩溃恢复过程示意图。
因而,当 Follower 服务器连接上 Leader 之后,Leader 服务器会根据自己服务器上最后被提交的 ZXID 和 Follower 上的 ZXID 进行比对,比对结果要么回滚,要么和 Leader 同步。
怎么对比呢?
这里就有必要了解下ZXID的组成结构了,如下图所示: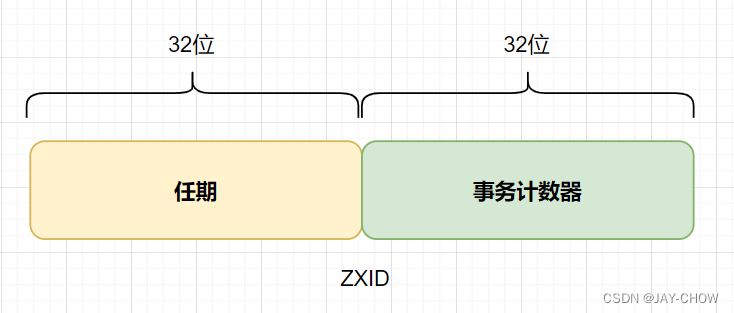
在ZAB协议的事务编号ZXID设计中,ZXID是一个64位的数字,其中:
低 32 位可以看作是一个简单的单调递增的计数器,针对客户端的每一个事务请求,Leader服务器在产生一个新的事务Proposal的时候,都会对该计数器进行加1操作;- 而
高32位则代表了Leader周期epoch的编号,每当选举产生一个新的Leader服务器,就会从这个Leader服务器上取出其本地日志中最大事务Proposal的ZXID,并从该ZXID中解析出对应的epoch值,然后再对其进行加1操作,之后就会以此编号作为新的epoch,并将低32位置0来开始生成新的ZXID。
ZAB协议中的这一通过
epoch编号来区分 Leader 周期变化的策略,能够有效地避免不同的 Leader 服务器错误地使用相同的ZXID编号提出不一样的事务Proposal的异常情况,这对于识别在Leader崩溃恢复前后生成的Proposal非常有帮助,大大简化和提升了数据恢复流程。
基于这样的策略,当一个包含了上一个 Leader 周期中尚未提交过的事务 Proposal 的服务器启动时,其肯定无法成为 Leader,原因很简单,因为当前集群中一定包含一个Quorum集合,该集合中的机器一定包含了更高epoch的事务Proposal,因此这台机器的事务 Proposal 肯定不是最高,也就无法成为 Leader 了。当这台机器加入到集群中,以Follower角色连接上Leader服务器之后,Leader服务器会根据自己服务器上最后被提交的Proposal来和 Follower服务器的Proposal进行比对,比对的结果当然是Leader会要求 Follower 进行一个回退操作——回退到一个确实已经被集群中过半机器提交的最新的事务Proposal。
这也就是ZK
原则二的实现原理:丢弃那些原来Leader的提案(Old Proposal)。4 参考
- 1 【Zookeeper学习】集群选举机制
- 搞懂分布式技术4:ZAB协议概述与选主流程详解
- 倪超. 《从Paxos到Zookeeper分布式一致性原理与实践》.



